Most advice on AI content optimization is wrong because it starts with writing style. That's not the primary problem. Your page usually fails much earlier. It fails at extraction, entity clarity, and retrieval.
If your team still thinks top Google rankings will carry you into ChatGPT, Gemini, Perplexity, and Claude, you're already behind. AI systems don't reward the page that “reads well” to a marketer. They reward the page that gives them a clean answer, a trusted entity, and a fact pattern they can reuse without guesswork.
At LLMBuddy, we've seen this gap clearly in Indian B2B SaaS. Brands invest years in SEO, then discover their category pages, comparison pages, docs, and solution pages are missing from AI answers. Meanwhile, clients like Chargebee (+74%), Whatfix (+84%), and Keka (+82%) improved AI visibility after structural changes, not after publishing more generic blog posts.
If you want a serious playbook for AI Content Optimization: How to Write Content for LLMs, stop asking how to “write better.” Ask how to become easier to retrieve, easier to trust, and harder to replace.
Why Your Top Google Ranks Are Invisible to AI
Your Google rank is no longer a proxy for AI visibility. That assumption is costing SaaS brands real pipeline.
BrightEdge data shows only approximately 20% overlap between LLM citations and Google's top 10 results, which means the page that ranks on Google often isn't the page AI assistants choose to cite. The same dataset also shows that AI search still drives less than 1% of total web traffic, but those visitors convert 23 times better than traditional search traffic, with revenue per visit up 254% year-over-year. The source is OmniBound's AI search statistics roundup.
That changes the economics. A small share of traffic can still be your highest-intent traffic.
Ranking is not the same as retrieval
Google rewards pages. LLMs retrieve passages, facts, and entities. That difference matters.
A founder will often tell me, “We rank in the top three for our core term.” Then we test the same topic inside ChatGPT or Perplexity and see a competitor cited instead. Usually the competitor did three things better. They answered the question faster, framed the topic in a way the model could extract cleanly, and built stronger machine-readable signals around the brand.
Practical rule: Stop measuring success only by blue-link rankings. Start checking whether your brand appears in AI answers for buying, comparison, and implementation prompts.
That's why AI visibility optimization is now a distinct discipline. It's not a rebrand of SEO. It's a different operating model.
What you should do this week
Pick five commercial pages. Then run the buyer prompt inside ChatGPT, Gemini, Claude, and Perplexity.
Use prompts like these:
- Category prompt “Best payroll software for Indian mid-market companies”
- Comparison prompt “Chargebee alternatives for subscription billing”
- Implementation prompt “How to reduce onboarding friction in digital adoption platforms”
If your page doesn't appear, don't assume the model is wrong. Assume your content is structurally weak for retrieval.
Adopt the GEO Mindset for LLM Retrieval
The biggest shift is mental. Stop thinking like an SEO team publishing pages for rankings. Start thinking like a retrieval engineer preparing content for extraction.
Google can send a user to your page and let the page do the persuading. AI systems often do the opposite. They summarize first, select supporting sources second, and send less traffic overall. Your content has to survive that compression step.
As of March 2025, Google's AI Overviews appeared in 13.14% of all searches and cut the position 1 click-through rate from 1.41% to 0.64%. The same source reports news publishers saw 30% to 40% fewer Google referrals. The data comes from SQ Magazine's AI SEO statistics roundup.
Informational content is getting squeezed
If your content strategy still depends on broad informational posts, you're exposed. AI summaries are eating that demand first.
That doesn't mean top-of-funnel content is dead. It means fluffy thought leadership is dead. The content that still holds up tends to sit closer to a buying decision. Product comparisons. Pricing explainers. Migration pages. Technical docs. Integration pages. Security pages. ROI pages.
Here's the mindset shift I push in audits:
| Old SEO thinking | GEO thinking |
|---|---|
| Rank the page | Become the extractable source |
| Increase clicks | Increase citations and inclusion |
| Write for dwell time | Write for retrieval confidence |
| Cover the topic broadly | Answer the query precisely |
Retrieval likes predictability
LLMs and RAG systems don't reward suspense. They don't care about your storytelling arc. They care whether a chunk of text can stand alone without breaking meaning.
That's why many polished SaaS pages underperform in AI environments. They start with brand messaging, abstract positioning, or layered persuasion. Humans may tolerate that. Retrieval systems won't.
If the first meaningful answer appears after three paragraphs, your page is late.
In our audits, the pages that win aren't always the most elegant. They're the most legible to the machine. Clear definitions. direct comparisons. explicit product context. named use cases. current facts. less rhetorical padding.
Your operating change
Move your best writers closer to product marketing and technical SEO. AI retrieval doesn't sit neatly inside one team.
A strong GEO workflow needs three things working together:
- Product clarity so the page says exactly what the software does
- Content structure so the answer can be lifted cleanly
- Entity consistency so the model knows who your brand is and what it should be trusted for
If you want the strategic layer behind that shift, start with Generative Engine Optimization. But don't treat it like a content trend. Treat it like search infrastructure.
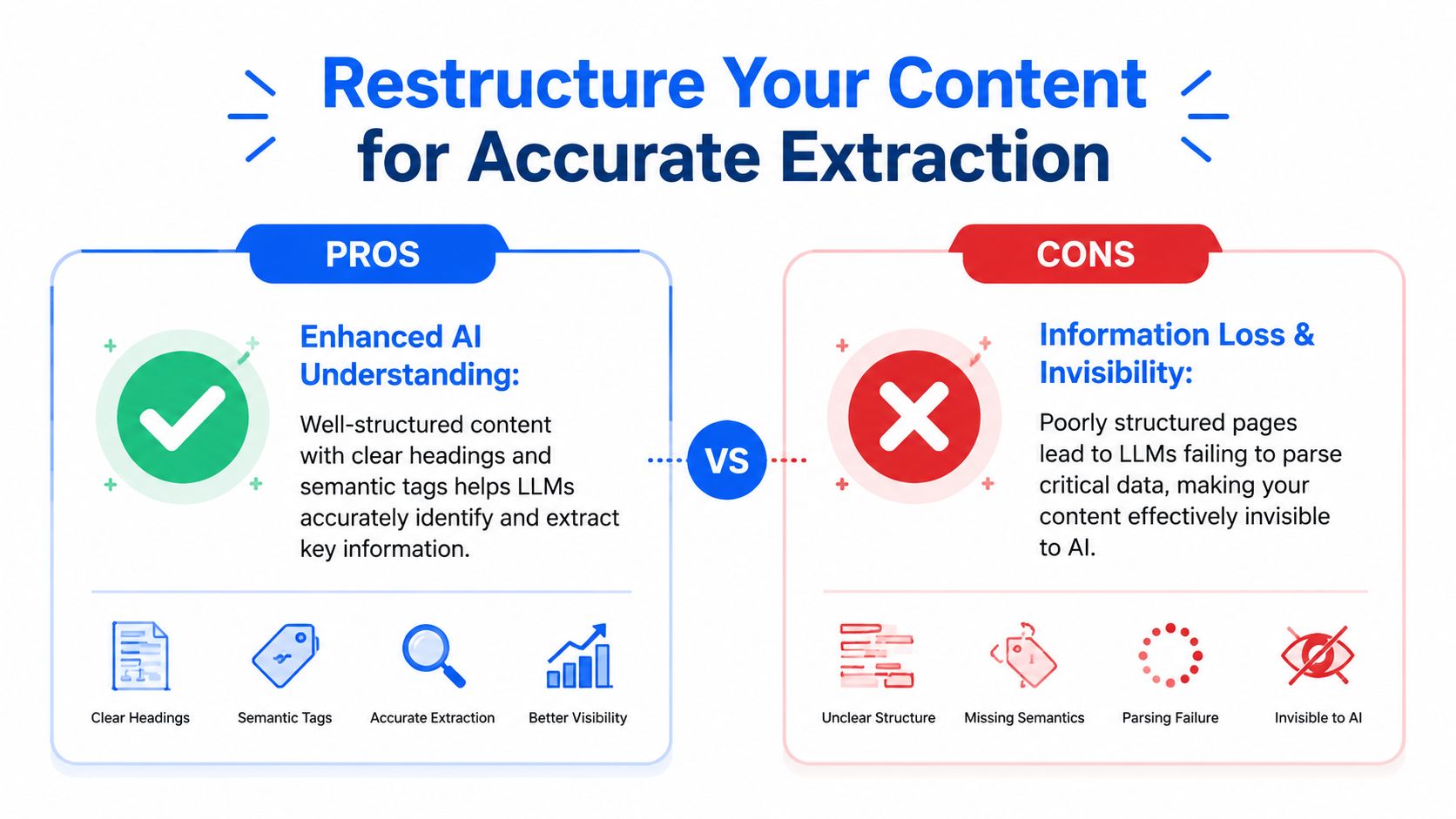
Restructure Your Content for Accurate Extraction
Most B2B SaaS pages fail because they bury the answer. LLMs don't reward delayed clarity. They reward front-loaded precision.
The fix is mechanical. Lead every section with a 40 to 60 word direct answer block. That structure increases citation rates by approximately 35% compared with paragraph-first formatting. Pair it with question-based H2s that mirror user queries and your page can appear in 28% more AI-generated responses, based on Averi's LLM optimization techniques).
Here's the page architecture I'd push on any Indian SaaS team trying to win citations in ChatGPT, Claude, Gemini, and Perplexity.
Put a quick answer under the H1
Your page should open with a short answer block immediately after the H1. Not a brand paragraph. Not a founder opinion. Not a generic intro.
If the page targets “What is usage-based pricing software,” the first visible block should define it in plain English. If the page targets “best employee onboarding software,” the first block should explain what makes a platform fit that use case and who it's for.
This is the simplest structural fix and the one that is frequently overlooked.
Turn headings into retrieval prompts
Your H2s and H3s should look like the actual questions buyers ask.
Bad heading: “Platform Overview”
Better heading: “What does this platform automate for finance teams?”
Bad heading: “Why choose us”
Better heading: “Why do SaaS finance teams switch from manual billing workflows?”
Question-based headings help the model map query to answer. Generic headings force inference. In retrieval, inference creates drop-off.
Field note: The best heading is often the prompt a buyer would type into Perplexity at 11:30 p.m. while comparing vendors.
Keep extractable blocks tight
One of the more overlooked rules is chunk size. Bay Leaf Digital's GEO guidance notes that content blocks should stay under 300 characters so generative engines can pull clean excerpts without truncation.
That doesn't mean every sentence must feel robotic. It means your high-value answers need tight boundaries. Long paragraphs blend claims together and reduce extraction accuracy.
Use this editing standard:
- One claim per block if the fact is commercially important
- Short paragraphs with two to four sentences max
- Precise nouns instead of vague pronouns like “it,” “this,” or “these”
- Explicit subject labels such as platform, feature, pricing model, integration, or workflow
A simple before and after model
| Weak version | Retrieval-friendly version |
|---|---|
| “Modern businesses need flexible systems that support growth and adapt to customer needs.” | “Usage-based billing software tracks consumption, calculates charges automatically, and helps SaaS finance teams invoice customers without manual spreadsheets.” |
| “Our onboarding solution improves adoption across teams and departments.” | “Digital adoption software guides users inside the product with walkthroughs, tooltips, and task prompts, which helps teams complete key workflows faster.” |
We applied this kind of rewrite discipline on high-intent content for Keka, and that work contributed to +82% visibility growth. The result didn't come from publishing more. It came from making existing pages easier to extract and cite.
If ChatGPT visibility is a priority, ChatGPT optimization starts. Not with prompts. With page structure.
Define Your Brand Entity with Technical Signals
Good formatting gets you parsed. Strong entity signals get you trusted.
A lot of SaaS teams treat brand authority as a vague reputation problem. For AI systems, it's more concrete. You need to tell the machine who you are, what topics you own, and which third-party references confirm that identity.

Use schema to remove ambiguity
The most useful starting point is JSON-LD. Don't stop at basic Organization markup. Extend it with signals that connect expertise and identity.
Averi recommends using knowsAbout arrays and sameAs properties linking to LinkedIn, G2, and Wikipedia, and reports that this can boost visibility scores by 22% in RAG-based systems in their testing. The same source also advises front-loading current statistics before drafting because fresher, specific data reduces omission errors. That guidance comes from the same Averi research cited earlier in this article.
For a B2B SaaS brand, the practical setup looks like this:
knowsAboutfields tied to product category, use case, buyer role, and technical domainsameAsreferences that point to your official LinkedIn page, G2 profile, and other established brand profiles- Consistent naming across homepage, product pages, docs, metadata, and third-party listings
If your site says one thing, your G2 profile says another, and your LinkedIn headline says a third, the model has to guess. Guessing is where citation loss happens.
Support deep pages, not just the homepage
Organizations often over-invest in homepage polish and under-invest in lower-hierarchy pages. That's a mistake.
Adobe's LLM Optimizer guidance notes that “agentic traffic often does not go to the home page but other pages lower in the hierarchy.” That matches what we see in audits. AI systems often hit docs, feature pages, integration pages, use-case pages, and implementation resources first.
So clean up those pages:
- Make the HTML plain and readable
- Keep key product details visible, not hidden behind tabs
- Add schema where the page answers a specific task or question
- Write direct task answers inside docs and support content
Your docs are no longer support assets only. They're retrieval assets.
Add llms.txt, but don't pretend it replaces real work
I'm in favor of an llms.txt file because it gives agentic crawlers a cleaner path to important content. But it's not a shortcut. If your pages are vague, bloated, or inconsistent, llms.txt won't save them.
Use it as a routing layer. Not as a strategy.
Build a Moat with Proprietary Data
Most GEO advice stops at formatting because formatting is easy to package. It's also not enough.
You can have perfect headings, clean schema, short paragraphs, and still lose citations if your content says the same thing as everyone else. Structure improves access. It does not create authority by itself.
A 2025 study by Onely found that “generic content gets ignored” and that “original research with proprietary data” is a top authority-building content type. That finding matches what serious SaaS teams are learning the hard way. If your article is just a better-arranged version of public information, AI systems have no reason to prefer you.

Generic advice is cheap
Every SaaS category now has dozens of “best practices” posts that say the same thing. AI can summarize those without you.
What AI can't easily replace is your internal benchmark data, implementation patterns, workflow failure rates, migration lessons, pricing observations, support trends, and expert interviews from people inside your company. That's the material that gives a model a reason to cite your domain.
This is why broad how-to content usually underperforms against pages that include one or more of these:
- Original benchmark slices from your product dataset
- Named case studies with verifiable outcomes
- Expert commentary from product, customer success, or implementation teams
- Current market observations tied to a specific segment or workflow
Frame data so models can lift it
Proprietary data only helps if you package it correctly.
Don't bury your best insight inside a PDF intro or a long narrative. Put the finding high on the page. Label it clearly. Explain what the data covers, who it applies to, and what the reader should conclude from it.
A good pattern looks like this:
| Data element | How to present it |
|---|---|
| Benchmark finding | Lead with one plain-English sentence that states the result |
| Scope | Add a short line explaining the customer segment or dataset context |
| Implication | State what the buyer or operator should do with the insight |
We've seen this work repeatedly in client content. Chargebee's +74% gain didn't come from generic educational publishing. It came from making high-intent pages more specific, more evidence-led, and more extractable. Whatfix's +84% followed the same principle. Not more words. Better source material.
If your content can be recreated by a generalist writer in two hours with Google results, it probably won't become a durable citation source.
The shift Indian SaaS teams need
Indian B2B SaaS brands often have a hidden advantage here. They sit on product usage data, support insights, implementation knowledge, and regional market context that global competitors don't explain well.
Publish that. Cleanly.
The market doesn't need another generic piece on onboarding, billing, HR automation, procurement workflows, or employee experience. It needs category pages and commercial content with facts only your team can state credibly.
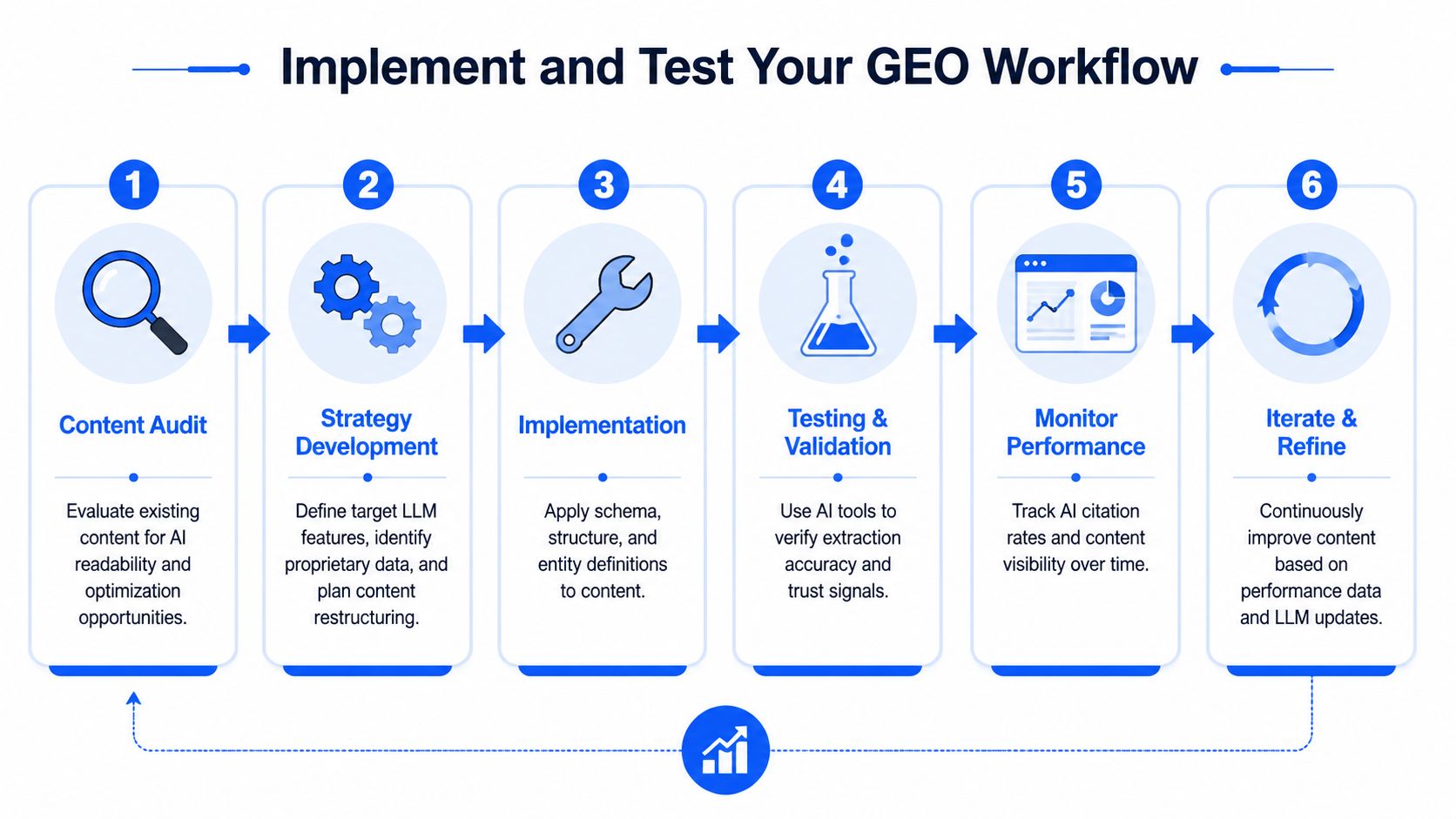
Implement and Test Your GEO Workflow
GEO fails when teams treat it like a content refresh. It is an operating system. Run it weekly, tie it to revenue pages, and measure what AI assistants say about you.
Start with pages that influence pipeline
Indian B2B SaaS teams waste time rewriting top-of-funnel blog posts while high-intent pages stay hard to extract. Fix the pages that show up during evaluation. That usually means comparison pages, solution pages, integration pages, migration pages, pricing explainers, product docs, and implementation guides tied to sales calls.
This is the sequence we use at LLMBuddy:
- Audit the page for retrieval readiness. Check whether the page answers a clear buyer prompt, names the brand and product entities correctly, and surfaces facts in extractable blocks.
- Rewrite the page structure. Add direct-answer intros, query-shaped subheads, short definition blocks, and tables that isolate key claims.
- Add technical support. Clean up internal links, schema, page hierarchy, and anchor paths so the model can reach the right page and interpret it correctly.
- Test in live assistants. Run the same commercial prompts in ChatGPT, Gemini, Claude, and Perplexity, then compare citation behavior.
For Chargebee and Whatfix, this work started on commercial and product-adjacent pages. That was the right call. AI assistants pull from pages closer to the buying decision far more often than founders expect.
Test the output, not just the page
Publishing is not the finish line. The output is.
Use prompt sets built from real buying journeys. Pull language from sales calls, demo notes, onboarding objections, and competitor comparisons. Then test four prompt types:
- Discovery prompts such as category selection or vendor shortlisting
- Comparison prompts that force trade-offs, alternatives, and differentiators
- Validation prompts around pricing logic, implementation effort, integrations, security, and fit
- Agent-style prompts asking the assistant to find setup docs, migration steps, or feature evidence
Track four outcomes every time: cited, paraphrased, misclassified, or ignored.
That diagnosis matters. If your brand appears but the answer is wrong, your entity definition is weak. If the model skips you entirely, the problem is usually page structure, crawl depth, or weak internal routing to the page that contains the answer.
Use a scorecard your team will maintain
Skip the fancy dashboard at the start. A shared sheet is enough if the fields are disciplined.
Track:
- prompt
- platform
- target page
- cited or not cited
- answer accuracy
- competitor mentions
- notes on hallucinations or wrong entity mapping
- action required
Review the sheet every month. Review it every two weeks if your category is crowded or your product narrative is changing fast.
Founders usually find outside pressure necessary. Someone has to decide which pages get rewritten first, which prompts reflect real pipeline conversations, and which technical fixes are blocking retrieval. If you want that baseline, run an AI search audit for your revenue pages and prioritize the pages that can change assistant output fastest.
Frequently Asked Questions About AI Content Optimization
Founders ask the wrong FAQ first. The question is not whether AI content optimization is real. The question is whether your revenue pages are structured well enough to be retrieved, extracted, and cited by ChatGPT, Gemini, Perplexity, and Claude. In our client work at LLMBuddy, that gap is usually obvious within the first prompt set.
GEO FAQs for B2B SaaS Leaders
| Question | LLMBuddy's Direct Answer |
|---|---|
| Do we need separate content for SEO and LLMs? | No. Rebuild the same high-intent pages so they work for both search engines and AI retrieval. Keep depth for buyers, but make answers extractable, define entities clearly, and keep each section self-contained. |
| Should we optimize the homepage first? | Start with the pages that answer commercial questions. Product pages, comparison pages, use-case pages, docs, and integrations get cited more often because assistants look for specific evidence, not brand slogans. |
| Does AI content optimization mean shorter content only? | Length is not the issue. Extraction is. A 2,000-word page can perform well if the answer appears early, the subheads are explicit, and key facts are easy to quote without rewriting the whole page. |
| Can AI-written content rank or get cited? | Yes, but generic AI copy is weak. Citation-worthy pages usually include original product detail, implementation specifics, pricing logic, customer context, or proprietary data that a model cannot assemble from boilerplate. |
| Which AI platforms should we test? | Test ChatGPT, Gemini, Perplexity, and Claude. They retrieve differently, summarize differently, and fail differently. A page that gets cited in one platform can be skipped or misread in another. |
| How often should we review GEO performance? | Review monthly at minimum. In crowded B2B SaaS categories, review every two weeks. Check citation rate, answer accuracy, competitor mentions, and whether the assistant mapped your brand to the right category and use case. |
One more point. AI visibility is shifting from passive summaries to task completion. Assistants increasingly pull setup steps, integration details, migration guidance, and feature proof from pages below the homepage. That is why Chargebee and Whatfix saw stronger citation lift after we reworked deep commercial and documentation pages, not after surface-level homepage edits.
If your docs are thin, your comparison pages dodge trade-offs, or your integration pages bury the answer under tabs and vague headings, assistants will route users to someone else.
If your SaaS brand wants a direct read on where it stands in ChatGPT, Gemini, Perplexity, and Claude, talk to LLMBuddy. We work with B2B SaaS teams in India to improve AI citations, entity clarity, and retrieval performance. If you want a practical starting point, request an AI search audit or book a demo. This playbook reflects how Ankur Pandey and the LLMBuddy team approach AI search visibility in practice.