

Legittai had a problem that more SaaS teams are running into every quarter. They could win on Google for a high-intent category term and still disappear inside ChatGPT, Gemini, and Perplexity.
That gap is what this Legittai from invisible to #1 in AI search full case study is about. I'm Ankur Pandey, lead strategist at LLMBuddy, and this project mattered because AI visibility has already moved into the buying journey for B2B software.
The Starting Point A Top Google Rank and Zero AI Visibility
Legittai came to us with a familiar story. Their category pages were strong, the product was real, and the positioning was credible. On paper, the brand looked discoverable.
But the buyer journey had shifted.
A prospect no longer had to search Google, compare ten blue links, and click through vendor pages one by one. They could ask ChatGPT for AI contract lifecycle management vendors, ask Gemini for compliant options, then ask Perplexity which platforms fit legal and revenue teams. Legittai wasn't showing up where those recommendation moments happened.
That's the commercial problem. Not the cosmetic one.
The market behind this shift is already large. One industry compilation values the AI search engine market at $18.84 billion in 2025 and projects it to exceed $50 billion by 2033. The same source says 94% of B2B buyers used a generative AI tool during their most recent purchase process. If you sell B2B SaaS, appearing in AI answers is now part of how vendor evaluation begins, not an experimental side channel, according to Omnibound's AI search statistics roundup.
Why strong SEO didn't save them
Google rankings still matter. They create demand capture, backlinks, and buyer education. But AI systems don't reward pages the same way a traditional search engine does.
They need confidence in three things:
- Entity clarity: who your company is, what your product is, and what category it belongs to
- Retrievable proof: product claims written in a format a model can extract and compare
- Trust signals: citations, reviews, and references outside your own site
Legittai had a solid website. What they didn't have was a machine-readable story that AI systems could repeat with confidence.
AI search failure usually isn't a content volume problem. It's a confidence problem.
That distinction matters for any founder or CMO reading this. If your team is still asking, “Why aren't our blogs showing up in AI answers?” you may be solving the wrong problem. The better question is, “Have we made our product easy for retrieval systems to understand, verify, and cite?”
The practical takeaway is simple. If your brand already ranks on Google but isn't getting recommended by ChatGPT, Gemini, Claude, or Perplexity, don't assume more content will fix it. Audit your entity signals first.
The Diagnosis An AI Search Audit Reveals the Gaps
When I showed Legittai the first audit readout, the problem became obvious fast. They were visible in traditional search and nearly absent in AI answers.

That gap is why we start GEO work with an audit, not a content sprint. A ranking report can show traffic potential. It cannot show whether ChatGPT, Gemini, Claude, and Perplexity can identify your company, retrieve your claims, and cite you with confidence.
For Legittai, the answer was no.
What the audit actually found
We ran prompt sets across the major AI platforms and reviewed the responses the way a buying team would. Could the model name the vendor? Could it describe the product accurately? Could it connect Legittai to the right software category and use cases?
The brand broke down at all three levels.
First, entity definition was inconsistent. Legittai was described in several reasonable ways across the site, but the language did not converge on one canonical identity. One page framed the product around AI contract management. Another stressed proposals. Another focused on compliance workflows. A human buyer can reconcile that. A retrieval system often treats those as separate signals and lowers confidence.
Second, key product proof was trapped inside prose. Important claims existed, but they were buried in paragraph copy instead of being stated in a format models could extract cleanly. That makes comparison harder. If an AI system is trying to answer "best contract automation software for mid-market teams," it favors vendors whose category, capabilities, and proof points are explicit.
Third, off-site validation was weak relative to the category. Legittai had a credible product and solid site content, but too few supporting references outside its own domain. In AI search, that matters. Models are more willing to recommend a vendor when the same story appears across multiple trusted sources.
Why we measure before we fix
A lot of SaaS teams want to skip this step because the gaps sound obvious once you see them. That shortcut creates problems later.
If you change pages, add schema, improve citations, and refine messaging without a clean baseline, you lose the ability to explain what worked. Then every improvement gets mixed together with product launches, new backlinks, branded search growth, or simple model volatility. That is bad strategy and worse reporting.
So we documented the before-state in detail. We saved prompt sets, answer snapshots, mention quality, entity accuracy, and citation presence before touching the site. That gave us a stable reference point for the work that followed.
If you want the same kind of baseline for your brand, start with an AI search audit for B2B SaaS teams, not another keyword report.
GEO starts with diagnosis. Until a model can identify, verify, and repeat your brand correctly, publishing more content usually adds noise, not visibility.
The GEO Strategy Entity Mapping Schema and Citations
Once the audit showed the weak points, the strategy became straightforward. Not easy. Straightforward.
We needed to make Legittai easier for AI systems to understand, easier to verify, and easier to cite. That meant changing the shape of the brand's information, not just rewriting a few landing pages.
The operating model looked like this.
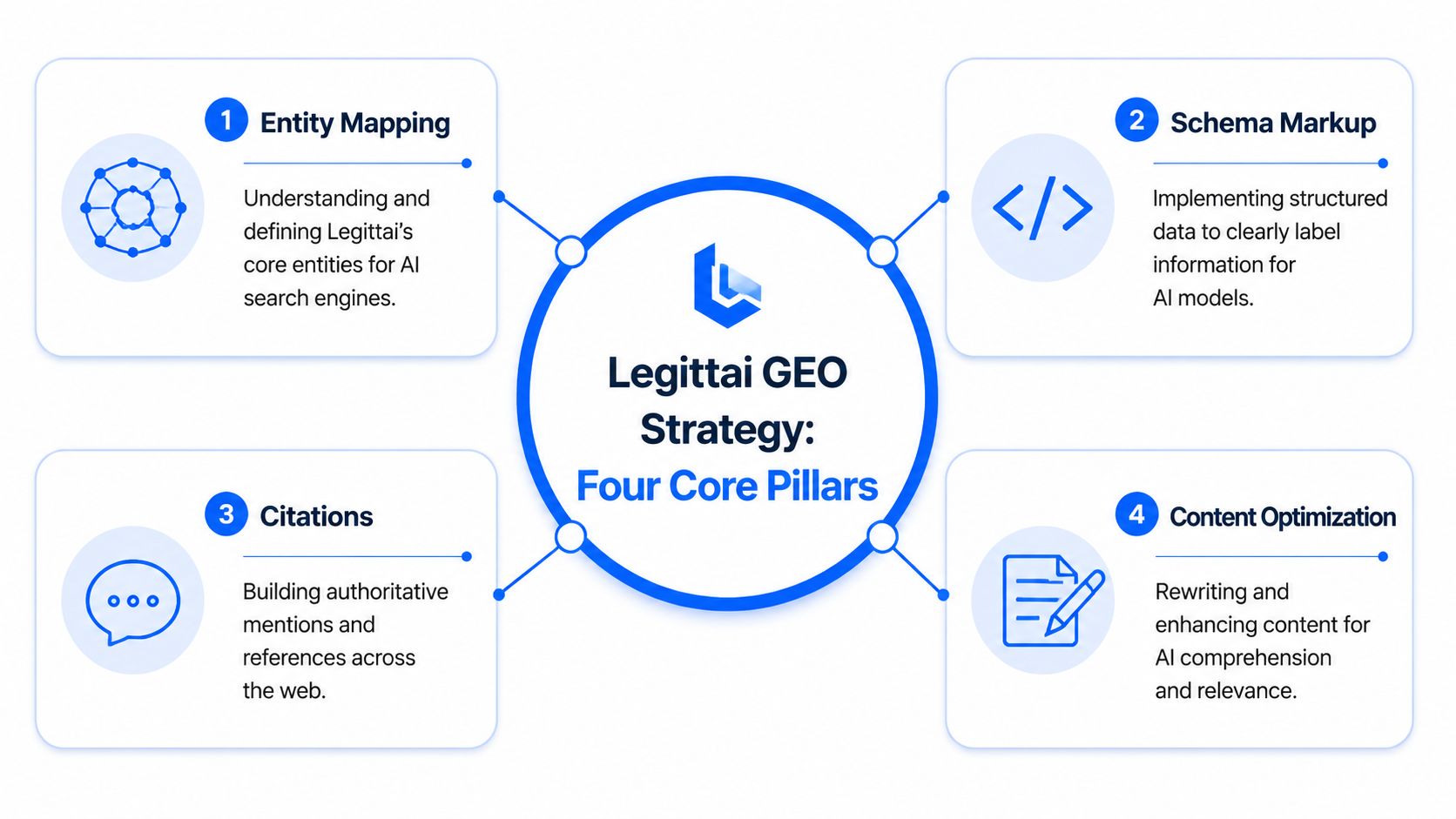
Pillar one was entity mapping
We created a canonical map of the company, product, use cases, buyer roles, workflow stages, and proof points. The point wasn't branding polish. The point was repetition with precision.
If one page says “AI CLM,” another says “contract automation platform,” and a third says “proposal and contracting suite,” the model may fail to consolidate them into one strong entity. We fixed that by standardizing primary labels and supporting descriptors across priority pages.
This is the same logic behind our Generative Engine Optimization work. AI systems need stable identities, not loose messaging.
Pillar two was schema and machine-readable structure
Microsoft's own architecture guidance for AI assistants emphasizes structured data. It recommends embeddings for semantic retrieval and structured records via APIs for high-signal attributes, which supports a simple rule for marketers and product teams: passages that are easy to parse and verify are easier to surface in AI answers, as described in Microsoft's AI assistant architecture guidance.
That shaped our implementation choices.
We marked up product capabilities, clarified compliance-related claims where the site already supported them, and reduced ambiguity in core product descriptions. We also added retrievable formatting patterns to page copy so a model could isolate a capability without reading a wall of marketing prose.
Pillar three was llms.txt and crawl guidance
This wasn't magic. It was hygiene.
We used llms.txt as a directional file to surface priority resources and reduce ambiguity about what pages represented the business best. It won't rescue a weak product narrative, but it can reduce noise for AI crawlers and retrieval systems.
Pillar four was citation pathways
Many SaaS teams underinvest. They assume their own site should be enough.
It usually isn't.
For recommendation-style prompts, AI systems often need outside corroboration before they confidently list a vendor. So we built a citation pathway around the places software buyers already trust: review platforms, category descriptions, partner pages, and industry mentions that reinforced the same canonical entity story we defined on-site.
A practical rule for your team: don't treat schema, page rewrites, and citations as separate workstreams. They only work when they reinforce the same product identity.
Execution Bringing the AI Visibility Plan to Life
The strategy was clear by this point. The hard part was turning the audit into assets that retrieval systems could use.
For Legittai, execution meant rebuilding the evidence trail page by page. We revised product language, split overloaded claims into distinct proof points, and aligned off-site mentions with the same entity definitions. That discipline is what moved the account. Generic AI content would not have done it.

We rewrote product pages for retrieval, not decoration
Legittai had an advantage many SaaS companies do not. The product itself was already built around structured contract data instead of static documents. That made the website fixable, because the underlying product model was strong even if the messaging was not.
We brought that structure onto the page. Dense paragraphs became short capability blocks. Broad feature copy became named workflows. We connected lead management, proposal generation, contract drafting, negotiation, signing, and repository analytics as one system with one vocabulary.
That matters because retrieval systems respond better to clean, stable language than to polished but vague marketing copy.
We turned implied claims into explicit evidence
A common failure pattern in B2B SaaS is simple. The site contains the right facts, but those facts are buried inside narrative copy written for humans skimming a page, not for models trying to extract a specific answer.
So we isolated the claims that showed up in commercial and evaluation prompts and gave each one a clear home.
That included:
- Category clarity: making the core product class explicit across key templates
- Workflow clarity: naming the stages in the buying and usage journey with consistent labels
- Trust clarity: separating compliance, governance, and control statements so they could support vendor-comparison prompts
If a useful fact is trapped inside a 200-word paragraph, an AI system may never treat it as a useful fact.
This was not a copy polish exercise. It was a retrieval engineering exercise applied to marketing pages.
We built the off-site citation path in parallel
Off-site reinforcement had to run alongside on-site edits.
We focused on business profiles, software review platforms, and category-relevant mentions that matched the entity map already defined on the site. The goal was consistency, not raw mention count. If external references describe the company one way and the site describes it another way, models hesitate.
Process usually breaks at this stage. Product marketing owns messaging. SEO owns templates. PR owns mentions. No one owns whether ChatGPT, Gemini, Perplexity, and Claude can retrieve the same company identity across all of them.
For brands wanting execution support, AI content optimization services can sit between product marketing and technical SEO to close that gap. That coordination was a major reason Legittai moved from a clean strategy document to measurable AI visibility gains.
The Results From Zero Mentions to Dominant Share of Voice
By the time we reached measurement, Legittai had already done the hard part. The site was clearer, the entity language was consistent, and the citation path matched the positioning. The remaining question was simple. Did AI systems change how they retrieved and recommended the brand, or did we just produce cleaner pages?
We answered that with a baseline-first scorecard, then tracked the same prompt sets across platforms after implementation.
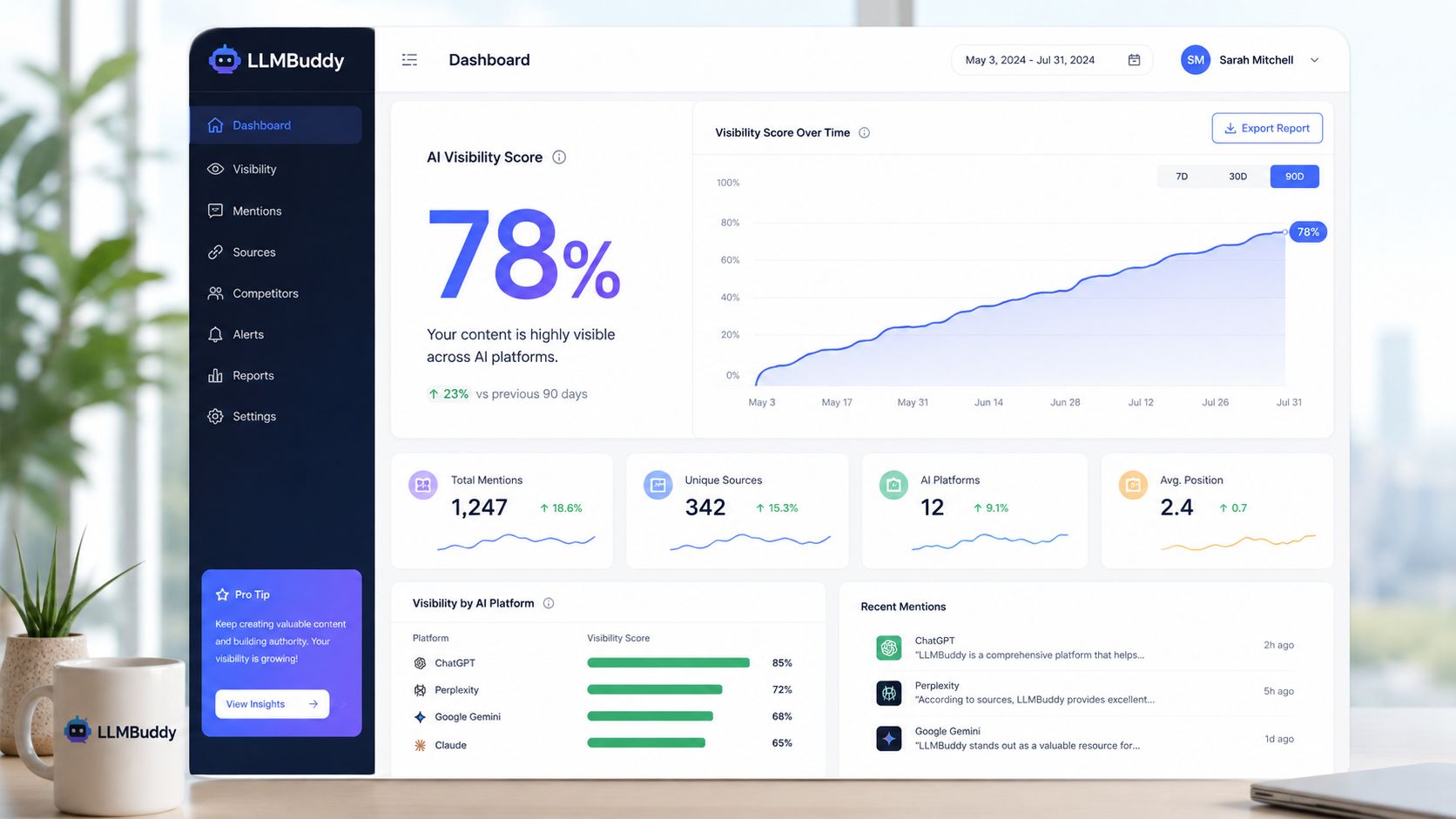
What changed
Within 90 days, Legittai's AI Visibility Score moved from 0% to 78% in our tracking. We also recorded 85% share of voice on Perplexity for commercial-intent queries, consistent citation in ChatGPT-4, and placement as a top recommended solution in Gemini.
Those gains did not come from one favorable prompt or a founder screenshot. My team compared answer structure, citation behavior, and recommendation rank before and after the rollout. The strongest lift showed up in prompts where models needed clear category definitions, product capability language, and external validation to answer with confidence.
That distinction matters because brand mentions alone can mislead a team. A model can surface a company once and still treat it as secondary, uncertain, or interchangeable.
How we judged whether the lift was real
As noted earlier, credible AI measurement starts with an audit and a fixed baseline. We followed that discipline from day one because AI outputs drift, prompt phrasing changes results, and brand demand can rise for reasons unrelated to GEO work.
So we did not ask only, "Did Legittai appear?"
We measured the quality of that appearance.
| Signal | What it told us |
|---|---|
| Mentions | Whether the brand entered the candidate set at all |
| Citations | Whether the model found enough support to reference the company directly |
| Recommendation position | Whether the brand was presented as a leading option or a supporting mention |
| Prompt class performance | Whether visibility improved across commercial, comparison, and compliance-led queries |
This is the part many SaaS teams skip. They report a single win, then assume the system now "knows" the brand. In practice, recommendation strength is built in layers. First the model recognizes the company. Then it cites it. Then it starts ranking it ahead of alternatives in high-intent prompts.
We have seen the same pattern in other B2B SaaS engagements. The shape of the improvement varies by category, but the rule is consistent. Clear entity framing plus credible citations produces stronger recommendation behavior than content volume alone. If you want to see how that pattern plays out across other engagements, our B2B SaaS GEO case studies show the difference between being indexed and being recommended.
The best proof of GEO impact is a repeated change in how multiple AI systems describe, cite, and rank your brand over time.
Key Lessons for Your B2B SaaS Growth Team
Legittai's project wasn't a one-off trick. It was a clean example of how AI visibility improves for SaaS brands that already have a real product, real category fit, and real buyer demand.
The first lesson is simple. Your brand is a data entity before it becomes an AI recommendation. If your site describes the company five different ways, AI systems won't unify that for you. Your team has to define the canonical version and repeat it across product, pricing, use case, and third-party surfaces.
What usually works and what usually fails
The strongest results tend to come from clearer structure, tighter entity language, and better evidence. The weakest results usually come from volume tactics.
Here's the pattern we see most often:
- Works: rewriting core money pages so product capabilities are explicit, scannable, and machine-readable
- Fails: publishing more top-of-funnel blogs while the product pages remain ambiguous
- Works: building citation paths on sources AI systems are likely to trust for software evaluation
- Fails: assuming your own website is enough proof
- Works: setting a baseline before implementation so you can separate actual lift from noise
- Fails: declaring success because one founder saw the brand once in ChatGPT
The operational takeaway
If you're a founder or CMO, don't hand this to content alone. GEO sits across product marketing, SEO, technical implementation, and reputation signals.
Your next internal meeting should answer four questions:
- What is our canonical product entity?
- Which commercial claims are explicit and machine-readable on-site?
- Where do trusted third parties reinforce those same claims?
- How will we measure mentions, citations, and recommendation rate separately?
That's the framework I'd use before spending another rupee on generic AI SEO content. If you want to pressure-test your current setup, the fastest next step is to request a review of your AI visibility and compare what your team believes the brand says with what ChatGPT, Gemini, Perplexity, and Claude can retrieve.
Frequently Asked Questions About GEO
How is GEO different from traditional SEO
Traditional SEO focuses on ranking pages in search engines. GEO focuses on making your brand retrievable, citable, and recommendable inside AI-generated answers.
There's overlap. Technical SEO still matters. Good content still matters. But GEO puts more weight on entity clarity, structured data, retrievable claims, and off-site trust signals. A page can rank on Google and still fail in AI answers if the model can't confidently classify or verify it.
How long does GEO take to show movement
You can often see early directional changes faster than a classic SEO campaign because AI systems can respond quickly once the retrieval layer improves. But serious programs still need disciplined execution.
What matters most is whether you've fixed the hard blockers first. If your category definition is unclear, your schema is thin, and your citations are weak, publishing more content won't speed anything up.
Can our in-house team handle this
Sometimes, yes.
If you already have a strong product marketer, a technical SEO who understands structured data, and someone who can coordinate citation development, you can build a capable in-house motion. The problem is usually coordination, not talent.
Most SaaS teams split this across departments. Messaging sits with product marketing. structured markup sits with web or SEO. Reviews and mentions sit with demand gen or PR. GEO works best when one owner is accountable for the full retrieval outcome across ChatGPT, Gemini, Perplexity, and Claude.
What should we measure first
Start with a baseline audit. Then separate the metrics.
Track whether your brand is mentioned, whether it is cited, and whether it is recommended as a top option. Those are different signals. If you merge them into one loose dashboard, you won't know what changed or why.
Is GEO only for large SaaS brands
No. Smaller category-focused companies can do very well if their positioning is clearer and more machine-readable than bigger competitors.
In fact, mid-market SaaS brands often move faster because they can align web, product marketing, and founder messaging without weeks of internal politics. The downside is that they usually have thinner citation profiles, so off-site reinforcement needs more deliberate work.
What's the fastest next step if we suspect we're invisible in AI search
Don't start by rewriting every blog post. Start by testing your commercial prompts across major assistants, documenting what each engine says, and comparing those answers against the product story you want buyers to hear.
If there's a gap, fix the entity layer and the proof layer first. Then expand from there.
If your SaaS brand ranks on Google but still disappears in AI answers, LLMBuddy can help you diagnose the gap and build the retrieval layer properly. The practical next step is to request an AI search audit or book a demo so your team can see where ChatGPT, Gemini, Perplexity, and Claude currently trust your brand, and where they don't.


