An AI Visibility Score is a composite 0 to 100 metric that measures how often and how prominently your SaaS brand appears inside AI answers, weighted by mention rate, recommendation rate, position, and sentiment. It is not another SEO metric. It measures whether ChatGPT, Gemini, Perplexity, and Claude include your brand in the answer, not whether Google lists your page.
Most advice on this topic misses the point. Founders obsess over the score itself, then panic when it isn't high enough. That's the wrong read. The score matters, but the underlying story sits underneath it. If your entity authority is weak and your citation pathways are thin, your score is only reporting the problem. It isn't the problem.
That matters a lot for Indian SaaS companies. Many teams still treat AI visibility like a content refresh project. It isn't. It's an authority and retrieval problem first, then a content structure problem second. We've seen this in client work led by Ankur Pandey, where brands with strong sites still underperform in AI answers until their entity signals and third-party references are cleaned up. The reverse is also true. Once those foundations improve, visibility can move fast. LLMBuddy's client results reflect that pattern with Chargebee +74%, Whatfix +84%, and Keka +82% in AI visibility improvement.
Your Google Rank Is a Vanity Metric
If your brand ranks on Google but doesn't appear in AI answers, you're losing buying intent before the click ever happens.
The old assumption was simple. Rank well, get traffic, convert traffic. That model is weakening because more buyers now start with AI assistants and stay there long enough to shortlist vendors. In that world, your homepage ranking is a lagging signal. Your mention inside the answer is the live signal.
According to Hamster Garage's AI visibility playbook, an AI Visibility Score is a composite 0-to-100 metric that quantifies how often and how prominently your B2B SaaS brand appears inside AI-generated answers, weighted by Brand Mention Rate, Recommendation Rate, positional prominence, and sentiment tone. That's the metric founders should be looking at if they want to know whether their category authority is translating into modern demand capture.
Why rankings mislead founders
Google rank tells you where a page sits in a list. AI visibility tells you whether your brand is part of the synthesized answer. Those are not the same thing.
A founder sees "we rank for payroll software India" and assumes the market sees the brand. Then a buyer asks ChatGPT for "best payroll platforms for fast-growing SaaS teams" and gets a list that excludes them. That's not a traffic issue. That's a trust and retrieval issue.
Practical rule: If your brand isn't recommended inside AI answers for comparison and alternative queries, your SEO win isn't protecting pipeline.
What to track instead
You need a weekly view of how AI systems frame your brand across real buying prompts. Not vanity keywords. Not blog traffic. Actual prompts buyers use during evaluation.
A simple way to think about it is this:
| Metric | What it tells you |
|---|---|
| Google ranking | Whether your page appears in search listings |
| AI Visibility Score | Whether your brand appears in AI-generated answers |
| Recommendation rate | Whether AI actively endorses your brand |
| Position in answer | Whether you're a lead option or a footnote |
If you're a B2B SaaS founder, stop asking, "Do we rank?" Start asking, "Do AI engines recommend us when buyers ask who to buy from?" That's the better question.
The Signals That Define Your AI Visibility
An AI Visibility Score doesn't move because you published another blog post. It moves because AI systems can clearly identify your brand, trust the evidence around it, and extract your claims without confusion.
Most Indian SaaS teams get it wrong. They treat visibility as a copywriting problem. It isn't. It's a signal architecture problem.
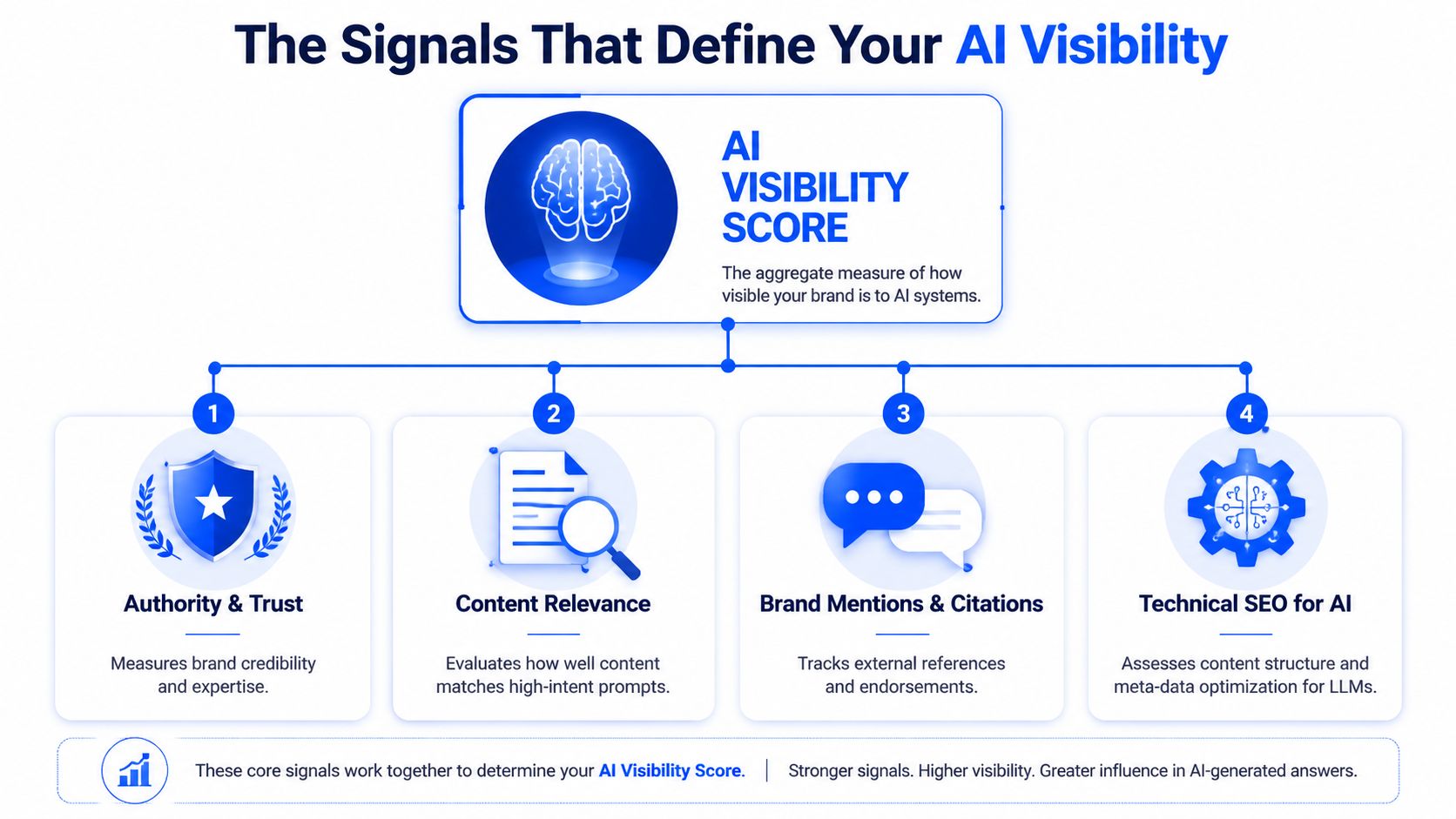
Entity authority comes first
AI engines need to know exactly who you are, what category you belong to, and how you're different from adjacent brands. If your brand name is generic, overlaps with a broader term, or lacks a clear knowledge footprint, models can blur you with competitors.
That confusion shows up fast in SaaS. A CRM tool, HR platform, or analytics product with weak entity signals may get omitted even if its content is solid. If the model isn't confident in the entity, it won't recommend it aggressively.
The fix isn't glamorous. You need consistency across your site, product pages, review profiles, company descriptions, and structured references. Your category language has to match. Your core use cases have to be explicit. Your brand should look like one entity everywhere, not five slightly different stories.
Citation pathways decide trust
A lot of AI visibility comes from what other trusted sources say about you. That's why review platforms, industry publications, and community references matter far more than most founders think.
Campaign Creators notes that 20% of AVS is derived from external citation pathways such as G2 and industry publications, and that these signals help LLMs resolve entity ambiguity in ways traditional rankings do not (their explanation of AI Visibility Score for marketers). If your only strong signals live on your own domain, you're asking the model to trust a biased source.
If third-party references are weak, AI systems may understand your content and still avoid recommending your brand.
Structure changes extractability
Even strong content fails if AI systems can't parse it cleanly. Three technical layers matter most:
- Schema markup helps models understand what the page represents and how facts connect.
- Page architecture makes key claims easy to extract, especially on comparison, alternative, and product pages.
- Control files like llms.txt help shape how LLM-facing systems interpret site content.
For SaaS brands, "answer-shaped" content beats essay-style content. Comparison tables, direct definitions, implementation pages, and concise truth pages often outperform broad thought leadership because they give models clean retrieval material. That's also why focused AI content optimization services tend to outperform generic editorial production.
The practical reading
Think of your score as the visible result of four underlying systems:
- Entity clarity decides whether the model knows who you are.
- Third-party citations decide whether the model trusts that identity.
- Content relevance decides whether your pages match buyer prompts.
- Technical structure decides whether the model can extract and reuse what you've published.
If your score is flat, don't just publish more. First ask which of those four systems is broken.
How AI Visibility Scores Are Computed
A serious AI Visibility Score isn't a vibe check. It's a scoring model.
The cleanest framework I've seen evaluates 20 high-intent SaaS prompts across four major AI engines on a 0 to 5 prominence scale, then normalizes the result into a 0 to 100 score. The formula is straightforward: (Total Raw Score / Maximum Possible Raw Score) × 100. The same framework also weights a primary recommendation at 3x a passing mention and applies a 15% bonus multiplier when a brand appears consistently across 3 of 4 engines (Derivate X's AI Visibility Score framework).

What the math is actually rewarding
This model doesn't reward noise. It rewards recommendation strength and consistency.
That means a brand mentioned casually in one Claude answer doesn't compare to a brand that shows up as a lead recommendation in ChatGPT, Gemini, and Perplexity. Founders often celebrate any mention. That's lazy analysis. Passing mentions don't mean you're winning the category. They often mean the model has weak confidence and is hedging.
Here's a simple interpretation table:
| Signal in the score | Why it matters |
|---|---|
| Prompt coverage | Shows whether you appear across buyer-intent queries |
| Prominence score | Shows where you appear in the answer |
| Recommendation weighting | Separates endorsement from incidental mention |
| Cross-engine consistency | Shows whether your authority travels across platforms |
Why your team should care about weighting
If your content team is optimizing only for mention frequency, they'll produce the wrong outcome. You don't need more accidental appearances. You need more first-position recommendations on the prompts that drive evaluation and demos.
This is also why score reviews need to happen at prompt level, not only as one dashboard number. A founder should ask: Are we weak on alternatives queries? Are we absent on "best tools" prompts? Are we visible in ChatGPT but not in Gemini? That's how you turn the score into diagnosis.
A score is only useful if you can trace it back to the prompts, engines, and recommendation strength behind it.
If you want that diagnosis done properly, start with a structured AI search audit rather than a one-off prompt test from your laptop.
Interpreting Your Score and Avoiding Common Pitfalls
Most founders misread the score in two ways. They either think a low score means failure, or they assume a moderate score means the job is done. Both are wrong.
Benchmarks matter. According to Trustable Labs' write-up on AI visibility for SaaS companies, the average unoptimized B2B SaaS brand scores between 23 and 35 on composite AI visibility metrics. That changes the conversation immediately. If you're sitting in the 40s without a serious GEO program, you're not failing. You're already above the unoptimized baseline.
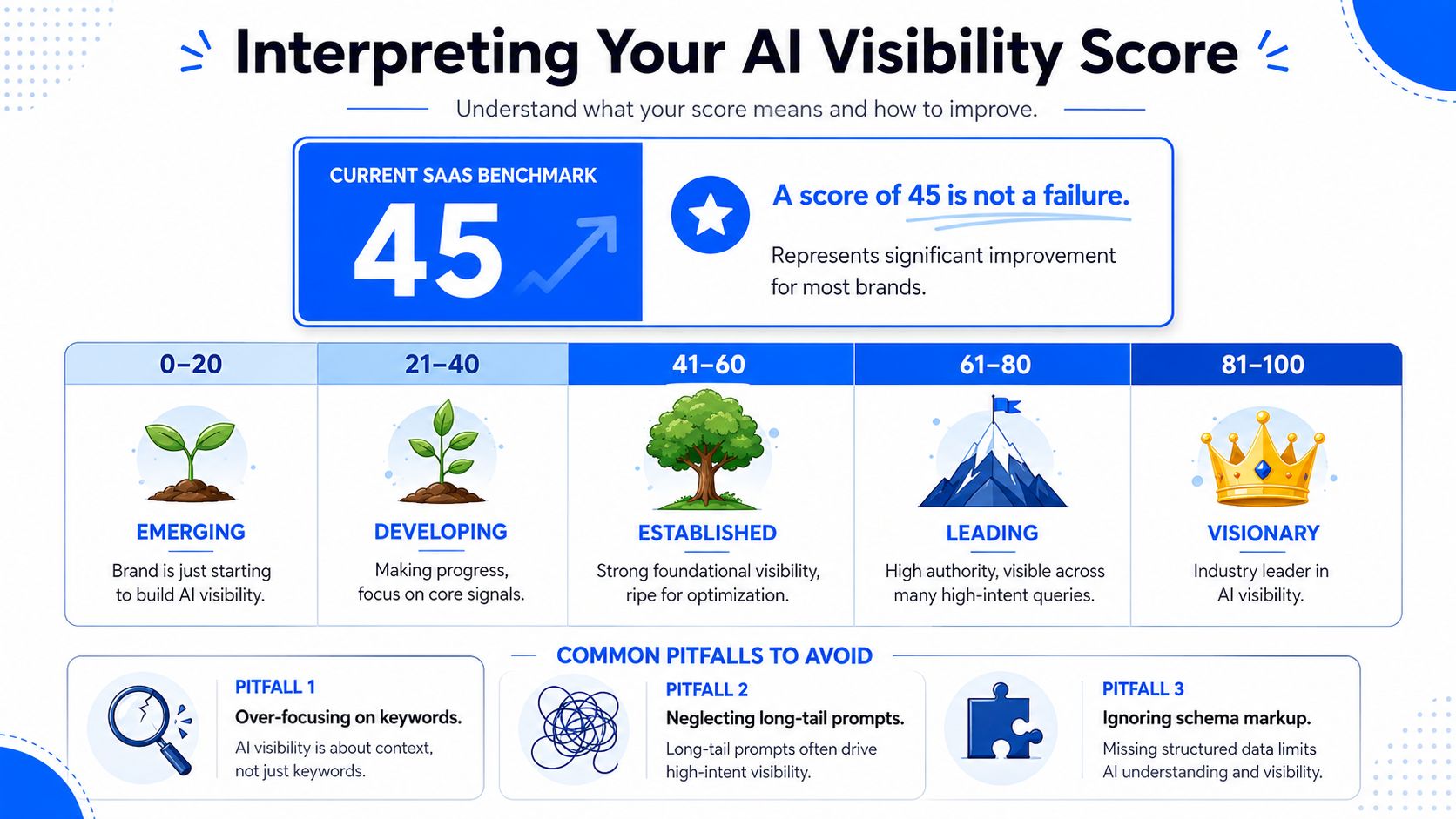
Read the tier, then read the cause
A useful benchmark model puts scores into four tiers: 0 to 20 low visibility, 21 to 50 moderate visibility, 51 to 75 good visibility, and 76 to 100 excellent visibility, based on Pranas' guide to AI visibility metrics. That framework is helpful, but only if you pair it with baseline reality.
A score of 45 can mean two very different things. For one brand, it's a sign of upward movement from a weak baseline. For another, it's stagnation because the brand should already dominate core prompts. Interpretation depends on category maturity, entity clarity, and competitive pressure.
The most common mistake founders make
They jump straight to content tweaks.
That usually wastes time. If your baseline is weak, the first problem is often entity confidence, not article quality. Trustable Labs makes that point clearly. Without a verified Knowledge Graph presence, scores can fluctuate heavily because models conflate similar software entities. In plain terms, the AI isn't sure who you are.
Here are the mistakes I see most often:
- Chasing a 75+ score too early. If your baseline is in the unoptimized range, your first target should be stability and inclusion.
- Confusing mentions with authority. You can appear occasionally and still not be treated as a serious recommendation.
- Ignoring entity groundwork. If Wikidata, G2, Product Hunt, and core brand references are weak or inconsistent, content alone won't fix the score.
- Reading one platform as the whole market. Strong ChatGPT visibility doesn't guarantee Gemini or Perplexity visibility.
Reality check: A score in the middle often means your brand has become recognizable but not yet trusted enough to lead the answer.
What to do with your current score
Use the score as a diagnostic tool, not a vanity badge.
If you're below the moderate range, fix identity and citations first. If you're in the moderate range, tighten comparison content and recommendation signals. If you're already in the good range, focus on cross-platform consistency and stronger lead-position appearances.
The wrong reaction is emotional. The right reaction is forensic.
The Playbook for Improving Your AI Visibility
A low AI Visibility Score isn't bad news. It's a map.
The teams that improve fastest don't guess. They run a repeatable GEO process. The broad pattern is now clear across the market. A documented benchmark shows 87% average growth in brand visibility scores within a 90-day optimization window for B2B SaaS companies using structured GEO work. That same benchmark ties the movement to entity signals, content structure, and third-party citations, not random publishing volume.
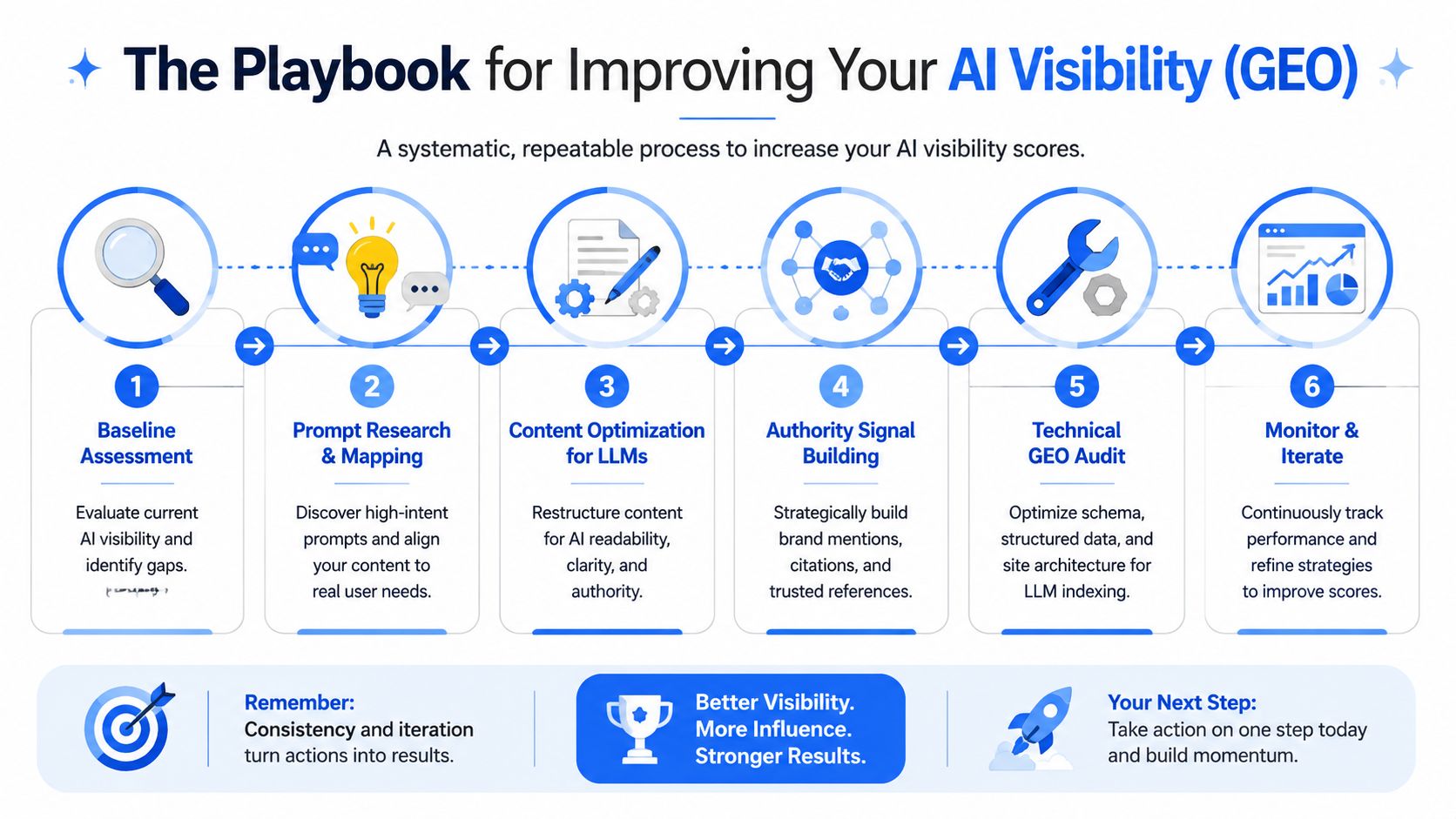
Start with the gaps buyers can see
The first move is an audit of real prompts. Not branded prompts. Buyer prompts.
That means testing alternatives, competitor comparisons, implementation questions, use-case queries, and "best tools" searches across ChatGPT, Gemini, Perplexity, and Claude. You need to know where your brand is omitted, where it's only a footnote, and where competitors are getting explicit recommendations.
Once that's clear, map every weak prompt to a missing signal. Sometimes the issue is missing comparison content. Sometimes it's no category page. Sometimes the brand has no credible external references, so the model avoids recommending it.
Build pages that answers can quote
The second move is engineering retrieval-friendly assets. Most SaaS blogs are too vague for this. AI systems prefer direct, extractable, citation-ready language.
That usually means:
- Comparison pages that clearly position your brand against named alternatives
- Use-case pages tied to industry, team size, or deployment context
- Truth pages with direct product facts, limitations, and differentiation
- Review and proof pathways that support claims with third-party validation
This is the essential work behind AI visibility optimization programs. You're not writing for a keyword list. You're structuring evidence so AI systems can retrieve and trust it.
Distribute authority beyond your own site
A lot of brands stop after content production. That's half the job.
You also need citation pathways. Strong profiles on platforms like G2 and Product Hunt help. So do mentions in respected industry publications and communities where buyers discuss tools in your category. Those references give LLMs a broader trust graph for your brand.
Many Indian SaaS companies underinvest in this aspect. They assume domain authority will carry them. It won't always. AI retrieval relies on corroboration.
Verify and keep iterating
The final step is verification. Re-run the same prompt set, compare recommendation strength, and watch platform-by-platform movement. You want to see not just mentions increasing, but lead recommendations increasing.
We've seen that pattern in LLMBuddy client work. Chargebee +74%, Whatfix +84%, and Keka +82% didn't happen because someone published more top-of-funnel blogs. Those gains came from disciplined GEO work around entity clarity, answer-shaped content, and citation reinforcement.
If you're deciding where to start, the order is simple. Audit first. Fix entity confusion second. Build retrieval-ready pages third. Strengthen third-party trust signals fourth. Everything else is secondary.
Monitoring AI Visibility and Measuring True Success
If you check your AI Visibility Score once a quarter, you're already behind. This metric moves with model behavior, competitive content, and citation changes. It needs weekly monitoring.
One metric matters a lot here. Share of Voice. The formula is simple: SOV = (Your brand mentions / Total brand mentions) × 100. Pranas explains that calculation while also making the bigger point that brands need platform-specific splits because performance can differ significantly between GPT-4, Gemini, and Perplexity. That's exactly how you should monitor it.
What success actually looks like
Success isn't just a rising score. It's a pattern.
You want to see your brand show up more often on high-intent prompts, appear earlier in the answer, and get framed positively versus competitors. A drop on one platform can tell you something specific. Maybe Perplexity is pulling newer competitor citations. Maybe Gemini is favoring better-structured comparison content. Maybe ChatGPT has stronger confidence in a rival's entity profile.
Track these views weekly:
- Overall AI Visibility Score for directional movement
- Share of Voice by category prompt set
- Per-platform visibility across ChatGPT, Gemini, Perplexity, and Claude
- Recommendation trend to separate inclusion from endorsement
- Sentiment pattern so you know how your brand is being framed
The founder-level interpretation
A dashboard should answer one business question. Are buyers more likely to encounter and trust your brand in AI-assisted research this week than they were last week?
If the answer is yes, keep compounding. If the answer is no, investigate fast. AI visibility is an operating metric now, not a reporting metric.
Frequently Asked Questions About AI Visibility
Is AI Visibility Score just a new name for SEO?
No. SEO measures rankings on a results page. AI visibility measures inclusion inside generated answers. The mechanics overlap in some places, but the outcome is different. Your brand can rank well and still be absent from ChatGPT, Gemini, Perplexity, or Claude. That's why founders who treat this as "SEO with a new label" usually move too slowly.
What's a good starting score for a SaaS brand?
It depends on whether the brand is already optimized. Industry data shows the average unoptimized B2B SaaS brand sits between 23 and 35, which is why founders shouldn't panic if their first benchmark looks low. Read the baseline before you judge the number. A middle-range score can mean solid progress if the entity foundations were weak.
How long does improvement usually take?
The strongest benchmark in this space shows 87% average growth in brand visibility scores within 90 days for B2B SaaS companies after structured GEO work. That doesn't mean every brand gets the same result. It means score movement can happen fast when the underlying issues are entity clarity, content structure, and third-party citations rather than product-market confusion.
Why does my brand show up in one AI tool but not another?
Because these platforms don't retrieve and synthesize information the same way. The overlap across platforms isn't total. One benchmark notes that roughly 32% of search queries create overlap where multiple AI platforms cite the same sources. That's exactly why platform-level tracking matters. If you're only testing one engine, you're flying blind.
Should early-stage SaaS companies care about this, or is it only for larger brands?
Early-stage companies should care even more, because they usually have weaker brand memory and fewer established citations. AI systems need clear evidence to trust and recommend newer vendors. If you're still building category recognition, entity clarity and external references can matter as much as your main website content.
What's the first practical step if I want my own score?
Get a baseline across real buyer prompts and all major engines. If you don't know where you're absent, where you're weak, and where competitors are beating you, every fix will be guesswork.
If your team wants a clear baseline instead of another vague AI search report, LLMBuddy can help. Start with an AI Search Audit or book a request demo to see how your brand appears across ChatGPT, Gemini, Perplexity, and Claude. If you're already investing in AI SEO services, Generative Engine Optimization, or ongoing case studies to prove impact, this is the missing measurement layer that tells you whether the market's new answer engines trust your brand.